


Mastering Kubernetes Spend-Efficiency
Read more

Databricks is a software-as-a-service platform for data engineering, data science, and analytics used by many companies, including Fortune 500 companies, startups, and research institutions. The powerful capabilities of Databricks for processing big data has made it the choice for businesses seeking to gain insights from their data.
However, these capabilities come at a cost – Databricks can be pretty expensive to use. The cost of running a Databricks environment can quickly spiral out of control if not properly optimized. This is a common problem with many cloud-based platforms, including Databricks. According to the 2022 Cloud Computing Survey by Foundry IDG, cost optimization was identified as the most significant challenge in implementing cloud strategies by 36% of IT decision-makers.
For this reason, cost optimization is a critical consideration for companies using Databricks so they can maximize the value they get while minimizing the costs of running it. Incorporating FinOps tools into your optimization strategy can simplify this process and improve cost control.
In this article, we offer a guide on Databricks cost optimization without sacrificing performance.
Understanding Databricks Costs
To effectively optimize Databricks costs, you should understand the platform's pricing model and the cost components that make up a Databricks environment.
Databricks pricing is based on a consumption model that charges for the resources used to run your workloads. These resources include compute, memory, and I/O. Each resource is measured in terms of Databricks units (DBUs), which is a measure of the total units of resources used per second. These DBUs are used to calculate the cost of running your workloads in Databricks.
Calculating the cost of running a Databricks environment can be a complex task that requires taking into account various factors, such as the cluster size, workload type, the subscription plan tier, and most importantly, the cloud platform its hosted on.
To determine the cost of a Databricks environment, you should know the DBU rate of the cluster, which varies depending on the subscription plan tier and cloud provider. Besides that, you'll need to factor in the workload type that generated the respective DBU, such as Automated Job, All-Purpose Compute, Delta Live Tables, SQL Compute, or Serverless Compute.
For example, suppose you have an enterprise Databricks workspace running on AWS. The jobs DBU list rate for this subscription plan tier is 20 cents/DBU. If you have a cluster consisting of 2 nodes, each running at 4 DBU/hour, the cost of running this cluster could cost $1.60 per hour (0.4 x 4 x 2).
To calculate the total cost of running your Databricks environment, you can use DBU calculators, which can help you estimate the costs of running specific workloads.
Databricks Billing Challenges
In the world of big data, using Databricks is akin to adding another piece to the puzzle, albeit one accompanied by an additional cloud bill. While this might look quite straightforward, it isn't.
Let's look at some of the challenges with Databricks:
- The manual effort required to integrate billing data: Integrating Databricks costs into other cloud spend data can require a lot of manual effort, especially if you don't have an automated process in place. This process alone can be extremely time-consuming and error-prone, which may eventually lead to inaccurate overall costs.
- Lack of robust spending constraints or cost alerting: Databricks doesn't provide robust spending constraints or cost alerting functions. That essentially means you can easily overspend and end up with unexpected costs and budget overruns.
- Dual charges and difficulty assessing overall costs: With Databricks, you get two primary charges: the cost of licensing the platform and the cost of running it on Amazon's EC2. Because of this, it's quite difficult to properly assess the total cost of Databricks.
- Difficulty tracking and allocating granular costs: Another issue with Databricks is the difficulty in differentiating costs associated with different types of capabilities, such as data exploration and insight, resulting in inaccurate cost tracking. Besides that, you can properly identify which business units are driving Databricks' spend.

Strategies for Databricks Cost Optimization
Use DBU calculators
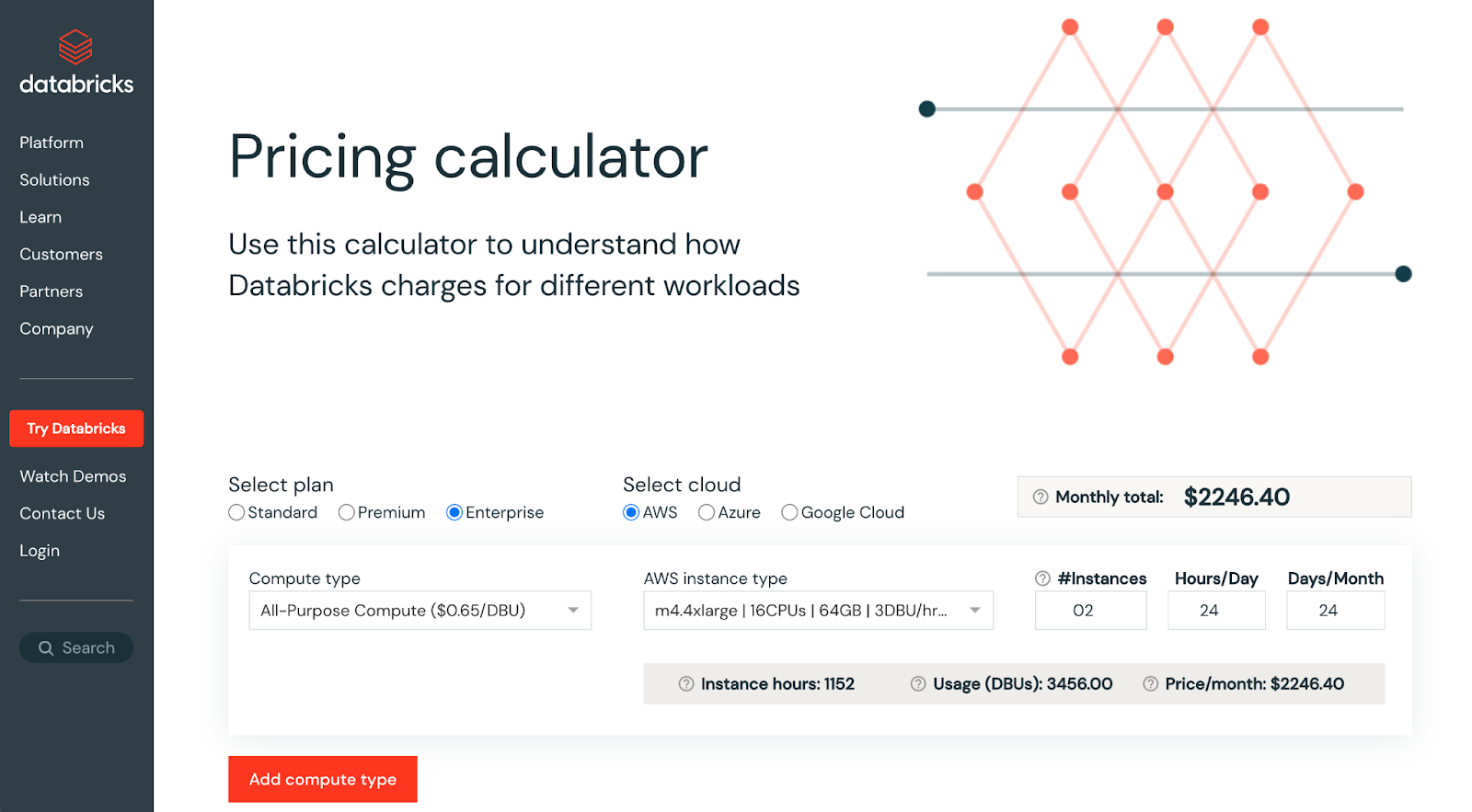
With Databricks' DBU calculator, you can estimate the cost of running specific workloads and identify areas for cost optimization. To determine the most cost-effective configuration for your workload, you can play around with different cluster sizes, instance types, and subscription plans.
By using the DBU calculator, you can better understand how factors such as the number of nodes, memory size, and disk size can affect your overall costs, allowing you to make informed decisions to reduce costs and optimize workloads.
Figure: Databricks pricing calculator
Choose the right instance
Choosing the right instance type is crucial for optimizing costs in a Databricks environment. AWS provides various instance families that are suitable for different types of workloads, each with its own configuration of CPU, memory, and storage resources.
For example, the M5 and C5 instance families offer high CPU-to-memory ratios, making them ideal for CPU-intensive workloads such as data processing and machine learning. On the other hand, the R5 and X1 instance families offer higher memory-to-CPU ratios, which make them more suitable for memory-intensive workloads such as data caching and in-memory analytics.
When selecting an instance type for your Databricks environment, it's important to consider both the performance and cost implications. Having an instance type that’s overprovisioned can lead to unnecessary costs, while choosing an instance type that is underprovisioned can result in slow performance and longer processing times.
Enable autoscaling
Databricks provides an autoscaling feature that can help you save costs by allocating resources based on workload demands. With this feature in place, you only pay for the resources you need - you won't overprovision or underprovision the resources needed to handle your workload.
Autoscaling works by automatically adjusting the size of your cluster based on workload demand. In times of low workload demand, cluster size is reduced to minimize costs. As demand increases, the cluster size is increased to ensure optimal performance.
To configure Autoscaling in Databricks, you'll need to specify the minimum and maximum number of nodes in your cluster, along with an Autoscaling policy that will determine cluster size according to workload demand. In addition, you can configure time-based Autoscaling, which adjusts the cluster size based on the time of day or day of the week.
Figure: Databricks cluster autoscaler
You can configure Databricks autoscaling in several ways. One option is to use the Databricks Standard Autoscaler– a built-in feature for adjusting cluster size according to CPU or memory usage demands. This particular option works for most scenarios and requires minimal configuration setup.
Alternatively, you can use the Databricks Enhanced Autoscaler, which offers more advanced customization options. With the Enhanced Autoscaler, you can optimize streaming workloads and enhance batch workload performance. This auto scaler ensures that no tasks fail during shutdown by proactively shutting down unused nodes.
Take advantage of spot instances
Databricks offers a cost-saving option through spot instances, which are virtual machines that cloud providers offer for bidding. You can save up to 90% on compute costs when you use spot instances. However, note that these instances may be reclaimed with a short notice period at any time. For example, AWS offers a notice period of 2 minutes, while Azure and GCP offer 30 seconds.
In GCP, you can use spot instances with Databricks using preemptible instances, which are similar to spot instances. By using this feature, you can reduce the underlying VM compute costs, leading to significant cost savings.
Even so, it's crucial to balance cost savings with interruption risks if the underlying cloud provider should reclaim the instance. Instead, consider using spot instances for workloads that are fault-tolerant and can be interrupted without causing a major disruption.
Leverage cluster tagging
Cluster tagging is important when optimizing resource usage and cost on Databricks. Having tags helps you to efficiently attribute costs and usage to specific teams in your company. However, to ensure that every cluster created is tagged with team-specific tags, administrators and data engineers must establish policies that enforce cluster tagging.
Figure: Databricks cluster tagging
By assigning a tag to the team leveraging the cluster, you can analyze usage logs to pinpoint DBUs and costs generated by each team using the cluster. The tags also cover the VM usage level, making it possible to attribute particular cloud provider costs to specific teams.
Optimize data processing workflows
You can reduce costs by optimizing your data processing workflows. A good strategy is to partition huge datasets into smaller, easily manageable chunks that can be processed in parallel. By partitioning your data, you can reduce the time required to process large datasets and reduce your workload's cost.
Caching is another useful technique, allowing you to save frequently accessed data in memory for fast retrieval and reuse. Cost-saving techniques such as filter pushdown can also be used to reduce costs. The goal of this technique is to push filters down to the data source, which may reduce the amount of data that needs to be transferred and processed. Minimizing data processing steps will reduce your workload's overall cost.
Monitor Databricks Cost with Finout
Regularly monitoring and analyzing your Databricks usage costs is an essential part of any cost optimization strategy. Even better, you should have granular data about your Databricks cost. By leveraging a cost management tool like Finout to keep track of your costs, you can take more proactive measures to optimize and reduce costs.
Before choosing a Databricks cost optimization and management tool, it's essential to note that you need features that can:
- Monitor and track Databricks cost across any cost type, account, service, or region to identify and optimize cost-saving measures
- Optimize cluster usage by autoscaling and auto-terminating so that Databricks clusters only run workloads when necessary and are terminated when not required.
- Take advantage of spot instances to save costs
- Reduce storage costs by using compressed formats and storing rarely used data in lower-cost tiers.
- Right-size clusters by using an appropriate number of worker nodes and the right type of instances for your workloads to ensure that you are using enough resources effectively.
- Effectively provide cluster tagging capabilities.
Finout is a holistic cost monitoring platform that combines your Databricks bill along with all your other providers, including AWS, Azure, GCP, Snowflake, and more. Besides offering all the features above, Finout also provides a way to use Databricks jobs and notebooks to automate your workload and reduce the need for manual involvement. Book a demo today to find out more.
Give it a try by booking a demo with our specialist today.